How to Train a Finance Deep Research Agent
1. Introduction
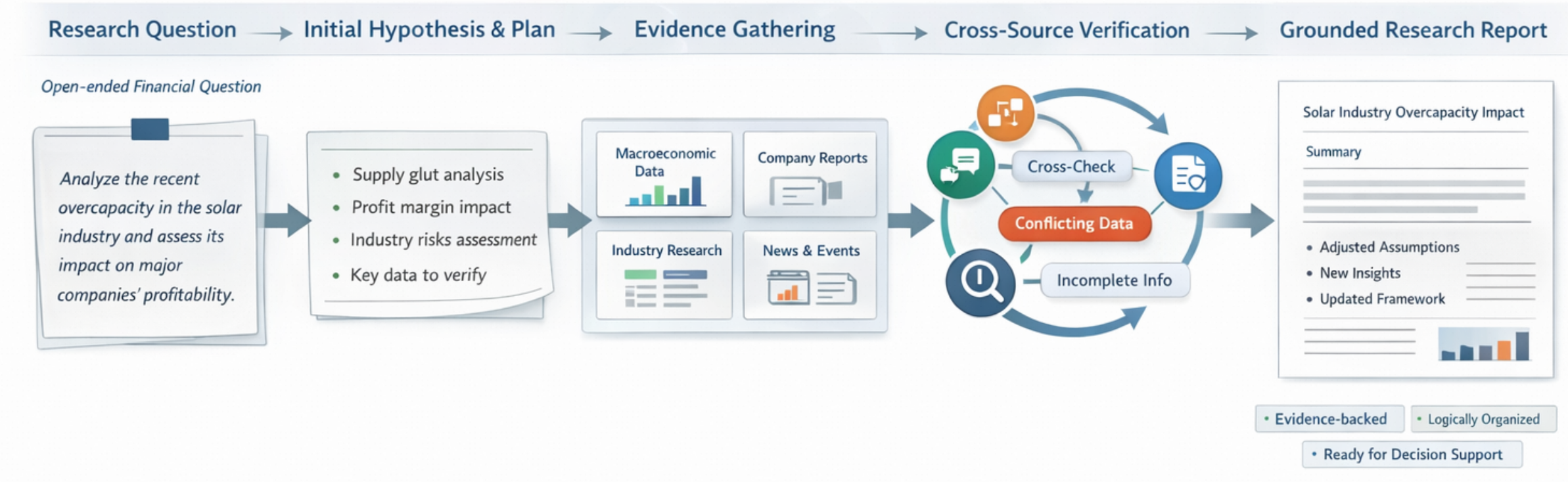
1.1 Defining Financial Deep Research
Financial deep research represents an ongoing investigative process rather than a one-off generation task. Real-world investment analysis involves forming preliminary judgments, clarifying research agendas, and defining verification paths before iterative retrieval and hypothesis refinement begins.
1.2 Core Challenge: Tensions Among Multi-Dimensional Objectives
Building such an agent requires balancing three interdependent — and often conflicting — objectives:
- Evidence Traceability: Every key claim must link to a verifiable source.
- Analytical Sufficiency: Research must identify contradictions and deliver value-added insights.
- Readability & Usability: Output must be information-dense and well-structured.
These objectives form a tension triangle where overemphasizing any single dimension undermines the others.
1.3 Limitations of Existing Paradigms
Workflow systems rely on rigid pipelines that fail to adapt to dynamic research questions. Supervised Fine-Tuning (SFT) mimics writing style but cannot teach research reasoning — it cannot teach a model how to decompose problems, resolve conflicting evidence, or iteratively revise judgments.
1.4 Our Approach
The shift was from implicit imitation to explicit optimization through reinforcement learning. Three barriers required addressing:
- Benchmarking for multi-turn tool use.
- Training data strategy focused on high-quality questions rather than ground-truth answers.
- Training infrastructure engineered for high-concurrency, multi-turn RL with caching and fault tolerance.
2. Defining Evaluation Criteria for Financial Deep Research
2.1 Limitations of Existing Benchmarks
Current benchmarks target single-turn, short-text, closed tasks unsuitable for research execution. Deep Research Agents must plan tool calls around unknown problems, organize evidence across long contexts, and perform open-ended analysis.
2.2 Benchmark Overview
The benchmark covers five domains (macro analysis, industry research, event interpretation, stock analysis, company research) with 30 total queries designed by experienced analysts. Design principles emphasize domain-wise breakdown and query quality over quantity.
2.3 Evaluation Focus: Analytical Sufficiency
Evaluation prioritizes whether the model organizes evidence and reasons from it, rather than stating conclusions without support. Pairwise evaluation treats references as baselines rather than rigid templates.
2.4 Evaluation Metrics ≠ Training Rewards
Evaluation metrics are not always suitable as RL rewards. Optimizing only for analytical sufficiency — without enforcing data authenticity or citation reliability — encourages shortcuts: skipping tool calls and fabricating data.
3. Training Strategy Design
3.1 Training Data: From Answers to Questions
RL relies on high-quality queries and well-designed rewards rather than (question, answer) pairs. The training set matches benchmark domain distribution and remains disjoint from evaluation data. A finance-specific query synthesis strategy produced approximately 1,000 high-quality training queries.
3.2 Reward Design: Multi-Dimensional Signals
Reward decomposition uses 1 core objective + 3 constraints:
- Core: Analytical Sufficiency (encourages evidence organization and insight).
- Constraints: Factuality, Citation Traceability, Presentation Quality.

This structure ensures deeper analysis without sacrificing grounding or usability.
Reward Calculation: Rule-Based Scoring
Scoring splits into two stages: extraction by Judge LLM, then deterministic rule-based logic. This improves stability and debuggability compared to end-to-end LLM scoring.
Positive Rewards and Negative Penalties
Simple penalties block invalid strategies, such as making almost no tool calls — accelerating early training by pruning unproductive exploration.
3.3 Predefined Workflow Scaffolding
Early training employed a Plan → Execute scaffold: models first outline analysis frameworks, then engage in tool interaction. This establishes stable patterns without locking the path.
4. Building Infrastructure for Training
4.1 From "Usable Tools" to "Trainable Environments"
In RL, the tool system functions as the environment itself. Financial data should be provided in computable, citable formats through unified interfaces like Finance-MCP, which standardizes diverse data sources while enabling call-chain tracing.
4.2 Three Training Environment Challenges — and Solutions
Cost. GRPO generates multiple trajectories per query, repeating identical tool calls. The fix: decouple tool execution into an EnvService layer with MongoDB caching.
Determinism. Non-deterministic tool responses make reward changes uninterpretable. Caching ensures identical inputs yield identical outputs.
Robustness. Single-point failures must not crash training. Implementation includes tool-call retries, fault-tolerant parsing, safe scoring degradation, and Judge LLM fallbacks.
5. Experimental Results
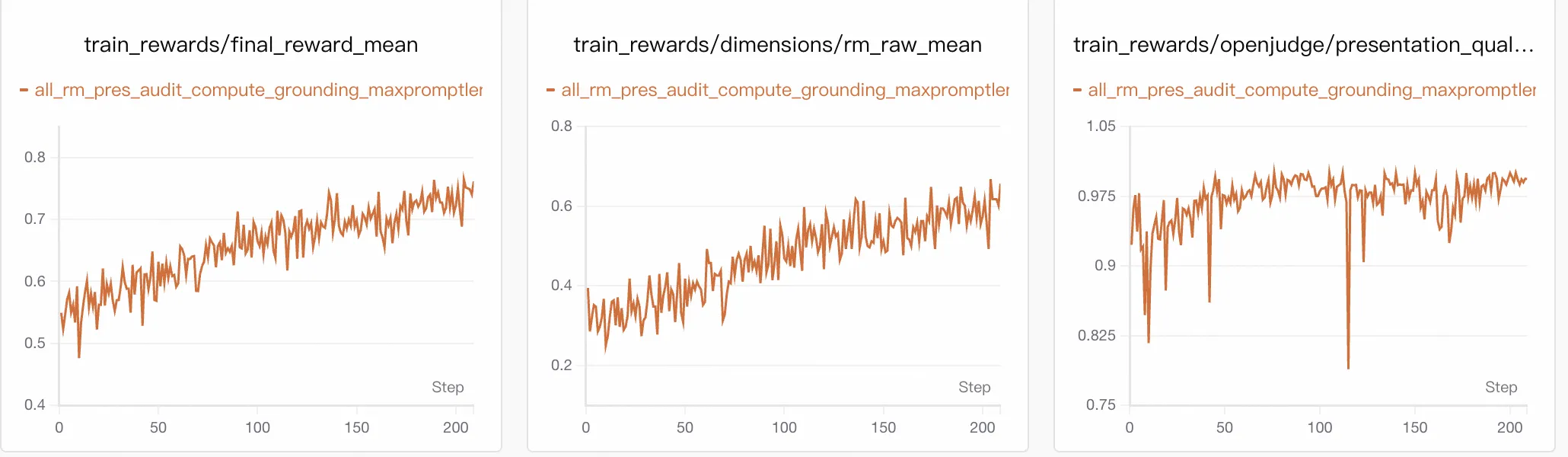
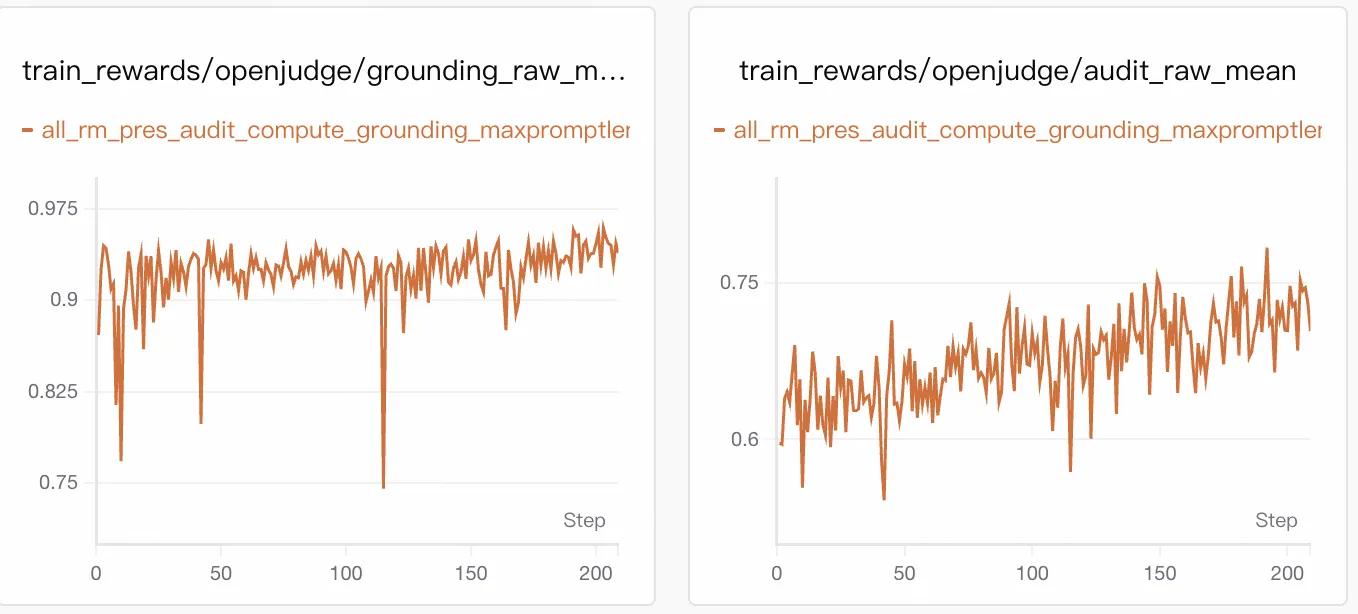
5.1 Training Dynamics: Gains from Analytical Capability
Final reward rose from approximately 0.54 to 0.75, with the largest gain from analytical sufficiency (increasing from ~0.30 to >0.60). Constraint metrics remained stable:
- Presentation > 0.95
- Grounding ≈ 0.90–0.95
- Audit rose slowly from ~0.60 to ~0.73
5.2 External Evaluation: Gains Beyond Finance
On DeepResearch Bench, the method scored 0.476, outperforming baseline models and Claude 3.7 (0.422). Improvements span both finance and non-finance subsets, suggesting RL reinforced a transferable research process, not just financial style adaptation.
| Model | Finance | Others | Overall |
|---|---|---|---|
| Qwen3-30B-A3B-Instruct | 0.184 | 0.118 | 0.127 |
| Tongyi DeepResearch | 0.296 | 0.274 | 0.277 |
| Claude 3.7 | 0.417 | 0.423 | 0.422 |
| Ours | 0.479 | 0.475 | 0.476 |
5.3 Case Study
Post-RL improvements included stronger entity selection, expanded evidence coverage (from ~10 to ~21 citations), coherent analytical structure, and abstracted patterns rather than descriptive summaries.
6. Pitfalls and Reflections: Engineering Realities of RL Training
6.1 Environmental Instability Encourages Shortcuts
Real financial APIs suffer rate limits and timeouts. Models exposed to instability avoided tool calls and fabricated data. Caching and error isolation are core training requirements rather than optimizations.
6.2 Capability Improvements Are Asynchronous
Under multi-dimensional rewards, capabilities improve at different rates. Easily optimized dimensions advance first while integrated reasoning lags. Temporary metric dips are normal — avoid frequent reward-weight tuning.
6.3 Evaluation Stability > Complexity
In RL, reward variance corrupts advantage estimation. Separating extraction (LLM-based) from scoring (rule-based) reduces flexibility but improves stability and debuggability.
Key Requirements for Minimal Reproduction
| Core Module | Minimum Requirement |
|---|---|
| Foundation Model | Basic multi-turn tool-use capability or SFT-aligned baseline |
| Data Engine | Small, diverse seed queries; no ground-truth answers needed |
| Tool Execution | Unified structured interface with call-chain tracing |
| Reward Design | Analytical sufficiency as core; factuality, grounding, presentation as constraints |
| Evaluation Infra | Pipeline combining semantic extraction and rule-based scoring |
| Training Infra | Noise isolation, call caching, and safe degradation for edge cases |
For financial deep research, the hardest part of RL is not "how to update the model," but "how to present a learnable environment."
One-Sentence Summary
Training a Financial Deep Research Agent requires defining good research and translating it into evaluable, feedback-rich, optimizable signals.
References
- Finance-MCP
- AgentScope
- AgentScope-Samples
- Xie, Q., et al. (2024). FinBen: A Holistic Financial Benchmark for Large Language Models. arXiv:2402.12659
- Du, M., et al. (2025). DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv:2506.11763