PawBench v1.0: Measuring General-Purpose Agents Reproducibly
Over the past year, general-purpose agents have moved beyond demos and into real workflows. They can write code, organize information, operate web pages, process files, and carry out longer task chains that involve tool calls, workspace reads and writes, and multi-step execution.
That shift makes the evaluation problem more concrete. If the same model runs inside different agent harnesses, how much does performance move? When a task fails, did the model misunderstand the goal, was the right tool missing, was the workspace misconfigured, or was the completion check too loose? A final success rate alone cannot answer these questions.
PawBench is built to answer exactly that question.
PawBench targets personal-assistant and general-agent scenarios. It evaluates the base model and the harness that runs it. In this article, a harness means the agent runtime: it assembles prompts, exposes tools, manages the workspace, isolates the environment, injects skills, and decides when the agent should continue or stop.
Put differently, the model defines what the agent may be capable of, while the harness determines whether that capability can be used reliably in real tasks. PawBench puts both sides into the same evaluation matrix.
- Project: https://github.com/agentscope-ai/PawBench
- Leaderboard: https://agentscope-ai.github.io/PawBench/
- OpenJudge: https://github.com/agentscope-ai/OpenJudge
- OpenJudge Website: https://openjudge.me
[!NOTE]
PawBench is part of the OpenJudge ecosystem. It follows OpenJudge's evaluation-driven optimization philosophy, with a specific focus on the joint effect of LLM × Harness.
How PawBench v1.0 Is Built
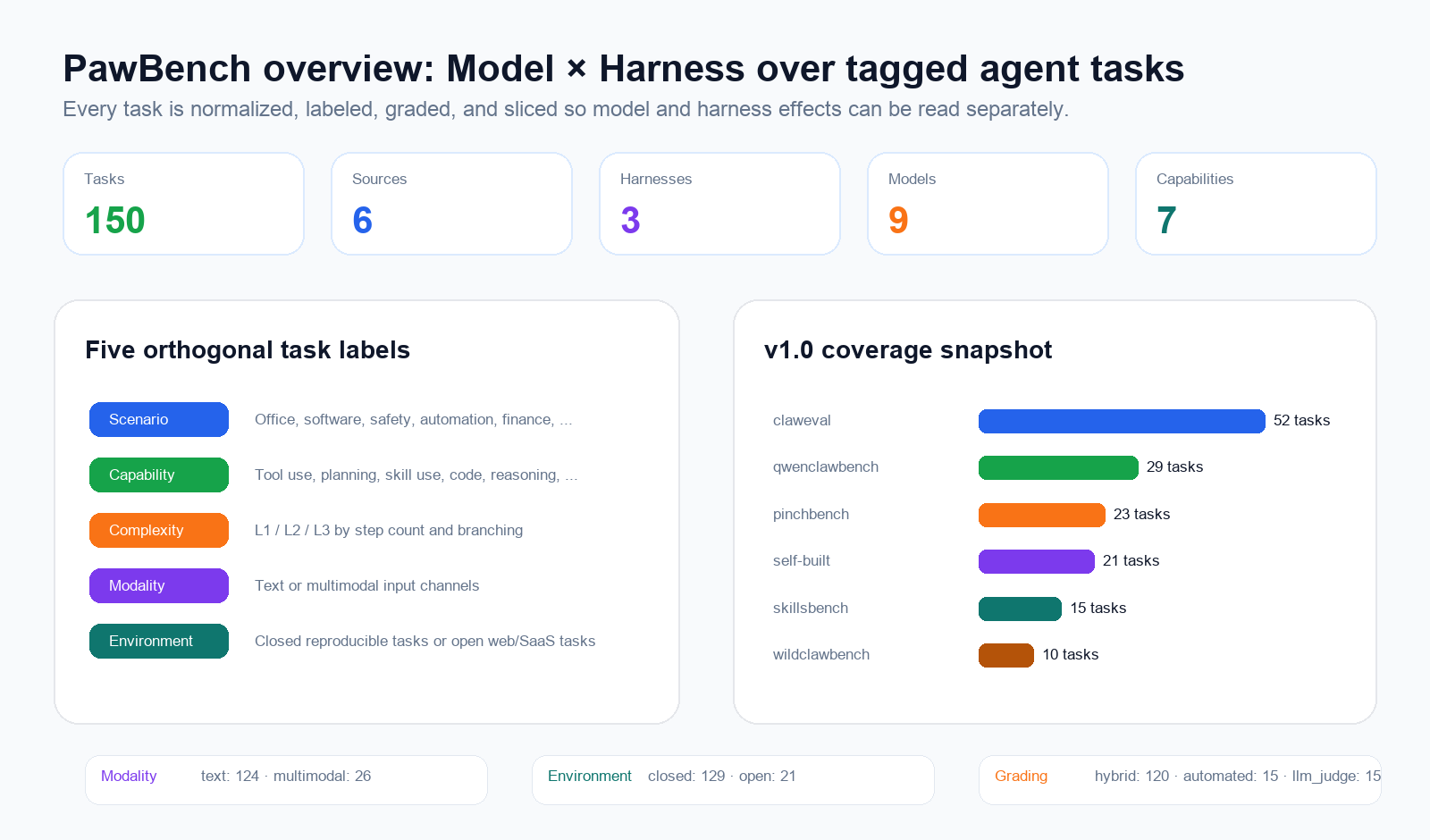
PawBench v1.0 is more than a model leaderboard. It evaluates models, harnesses, and tasks as a cross product.
This release samples 150 tasks from six high-quality agent benchmarks: claweval, qwenclawbench, pinchbench, qwenpawbench, skillsbench, and wildclawbench. Each task is tagged along five dimensions:
- Application scenario: office collaboration, software engineering, automation scripts, multimodal content generation, and more.
- Atomic capability: tool use, Skill use, planning, logical reasoning, self-verification.
- Complexity: L1 / L2 / L3, so the benchmark cannot be solved by only easy tasks.
- Input modality: text-only tasks versus image, audio, video, and other multimodal tasks.
- Runtime environment: offline sandbox tasks versus open-environment tasks that require web search or web retrieval.
The full matrix is 9 models × 3 harnesses × 150 tasks, for 4,050 test cells. The three harnesses are Hermes, OpenClaw, and QwenPaw. All tasks run inside Docker sandboxes, and PawBench keeps execution traces, grader artifacts, and environment snapshots for later slice analysis.
The final score combines automated graders, including rule checks and sub-assertions, with LLM-as-judge for more semantic outputs. Scores are normalized to the 0–1 range and reported as percentages in this article.
1. Score Matrix: Performance Comes From the Model–Harness Pair
Start with the text-task matrix.
The matrix answers two questions at once: how much the same model moves across harnesses, and how much the score changes when we swap the model under a fixed harness.
Text Score Matrix: Scores Come From the Model–Harness Pair
Using the Text tab keeps the comparison less affected by multimodal coverage. Read across a row to see harness effects, and down a column to see model effects. Darker cells mean higher scores.
Two observations stand out.
- Models and harnesses both shape the result. Model capability still matters:
claude-opus-4.6stays above 76 across all three harnesses, so a strong model remains strong in different runtimes. But weaker models are more harness-sensitive:qwen3.6-35b-a3bmoves from 57.9 on Hermes to 70.4 on QwenPaw. - The harness gap is comparable to a model upgrade. On text tasks, QwenPaw averages 75.4, OpenClaw 74.8, and Hermes 70.0, leaving a 5.5-point spread. More concretely,
qwen3.6-plus + QwenPawscores 76.5, higher thanqwen3.6-max-preview + Hermesat 70.2. A good harness can let a smaller model punch above its weight, but the real effect comes from model capability and harness support working together.
2. Where Models Differ: Strengths and Weaknesses by Slice
If the story stopped here, PawBench would just be a harness benchmark. But the 4,050 cells reveal something else: different models fail in different ways.
To focus on model-side differences first, we fix the harness to QwenPaw and slice the same submissions by task labels. This removes the largest environment variable from the previous matrix and makes the model profiles easier to interpret.
QwenPaw Slice View: Three Differences Hidden by the Aggregate Score
These are QwenPaw-only results. The three cards map to scenario, capability, and modality labels.
Choose models by task type. claude-opus-4.6 sits in the top tier by aggregate score, with strong average performance and good stability. But once we split the results by top-level scenario, it ranks first in only 4 of 11 scenarios. Manufacturing Engineering and Software Engineering are led by qwen3.6-max-preview, while Data Analytics is led by qwen3.7-max. The aggregate score is useful for a first pass; actual model selection should still start from the workload.
Qwen3.6 35B/A3B vs. Max: The Gap Shows Up in Long-Horizon Tasks. Within the Qwen family, bigger models do not mainly separate themselves on simple Q&A. The gap is clearer on Math Computation, Planning, and Tool Use, where the task requires multi-step execution and sustained planning. Under QwenPaw, qwen3.6-max-preview has the most complete capability profile; qwen3.7-max leans more toward open-environment and data-analysis tasks.
Multimodal remains a shared weak spot. After removing text-only models without native multimodal capability, every comparable model scores lower on multimodal tasks than on text tasks under QwenPaw: claude-opus-4.6 by 6.1 points, deepseek-v4-pro by 8.0, and qwen3.6-35b-a3b by 12.4. This is not one model's outlier failure. It reflects the combined difficulty of image understanding, information extraction, cross-modal reasoning, and tool-chain handoff.
Fixing one harness makes the model differences easier to see, but models do not run in isolation in real use. The next question is what happens when those differences are put back into different harnesses: which gaps get amplified, and which ones can be absorbed by better tools, state, and validation.
3. Model × Harness Pairing: Three Interaction Slices
PawBench can slice the 4,050 cells by model size, modality, task type, skill domain, and more, then compare those slices against execution traces. This shows how model capability and harness behavior interact. The model understands the goal, plans actions, and judges results; the harness turns tools, skills, state, and environment constraints into structure the model can actually use.
1. Smaller models need the harness to stabilize execution
The same model moves by up to 11.5 points across harnesses.
2. Skill use needs harness discovery and model follow-through
Skill tasks test both discovery and follow-through.
3. Web Search tasks depend on default availability
Default search / fetch decides how much routing the model must do.
Finding 1: Smaller Models Need the Harness to Stabilize Execution
Start with two models. claude-opus-4.6 is stable across the three harnesses, with only a 2.3-point spread. qwen3.6-35b-a3b, by contrast, moves by 11.5 points when only the harness changes.
| Model | Hermes | OpenClaw | QwenPaw | Δ |
|---|---|---|---|---|
| claude-opus-4.6 | 78.4 | 76.1 | 78.3 | 2.3 |
| qwen3.6-35b-a3b | 56.7 | 67.8 | 68.3 | 11.5 |
This shows that large and small models are not equally harness-sensitive. Larger models can often fill in missing context: they infer paths, filter a larger tool list, and check whether artifacts were actually produced. Smaller models are more brittle during execution. They are more likely to forget the current working directory, misjudge whether a file was written, or choose the wrong first tool when the tool list is too large.
Trace review shows three places where the harness failed to support that execution path.
(1) Missing artifact-level validation: many harnesses rely on the model saying "done" instead of checking whether workspace artifacts actually exist, whether diffs were generated, whether tests passed, or whether the path is correct. This makes premature completion easy.
(2) Loose path awareness and constraints: for example, Hermes did not clearly inject the current working directory into the prompt, nor did it strictly constrain write paths in tools like write_file. The model may believe it wrote the file successfully while the grader cannot find it in the standard workspace.
| Harness | Does it tell the model cwd / workspace? | Does file writing validate paths? |
|---|---|---|
| Hermes | No clear injection | No unified validation |
| OpenClaw | Explicitly injects workspaceDir | File tools and prompt share the same base |
| QwenPaw | Injects workspace path at runtime | File tools use unified workspace_dir |
(3) Oversized tool tables increase decision burden: the default tool counts differ substantially across harnesses: Hermes has about 65 tools, OpenClaw about 30, and QwenPaw about 15. More tools are not always better. A large tool schema consumes context and makes the first decision harder, especially for smaller models.
This slice is not saying "small models are bad," or that "a harness can replace model capability." The more precise conclusion is that smaller models need more external structure from the harness. Details like cwd, path constraints, tool selection, and artifact validation may be nice-to-have for a large model, but they can be the difference between completion and failure for a smaller one.
Finding 2: Skill Use Requires Harness Discovery and Model Follow-Through
Many users place Skills inside the project workspace as project-specific guidance. PawBench simulates that setup: each task-specific Skill is copied into the workspace to test whether the harness can discover and apply it. Compared with tool use, planning, and logical reasoning slices, all three harnesses struggle on the 17 Skill tasks.
This exposes two core issues. The first is insufficient active discovery by the harness. Except for OpenClaw, the other two harnesses do not actively load Skills from the workspace. If the harness only scans globally installed Skills and ignores the current workspace, the model loses the key instructions and has to explore on its own.
| Harness | Skill-task average | Automatically loads workspace SKILL.md? |
|---|---|---|
| Hermes | 44.6 | Scans ~/.hermes/skills/; easy to miss workspace Skills |
| OpenClaw | 52.5 | Scans workspace and renders into <available_skills> |
| QwenPaw | 44.5 | Scans by default but does not load workspace Skills |
The second issue is the model's own long-chain reasoning bottleneck. Even when the harness injects the Skill and places the signpost, the model can still fail during complex reasoning or precise computation. The harness can point the way; the base model still has to follow the path.
So the hard part is not merely having a Skill available. The whole chain has to work: the harness must discover the workspace Skill and expose its name, description, applicability, and invocation method where the model can see them; the model then has to decide when to use the Skill and follow the procedure. If either side breaks, the failure looks the same: the model bypasses the Skill and tries to solve the task with general reasoning.
Finding 3: Web Search Tasks Depend Heavily on Default Availability
Web Search tasks test the model's ability to search the web, fetch content, and do deeper research. PawBench does not assume the best-case setup where every search API key is configured. Instead, it recreates the default developer experience: clone a fixed version, add the LLM key, and run.
On these tasks, Hermes scores lower mainly because key tools are locked behind extra configuration. Although the source includes web_search and web_extract, they require external search API keys. In an environment with only the LLM key configured, the model cannot use them and must fall back to basic browser tools.
| Harness | Actual web tools in this run | Zero-config experience |
|---|---|---|
| Hermes | No web_search / web_extract; only browser-style tools | Needs extra keys |
| OpenClaw | web_search + web_fetch | Works out of the box |
| QwenPaw | Combined browser-style tool | No dedicated search |
OpenClaw has a better default experience: web_search can use keyless services such as DuckDuckGo, and web_fetch relies on built-in HTTP fetching. QwenPaw does not have a dedicated search tool, but its browser_use tool plus model knowledge can still handle basic web access.
This means Web Search scores reflect both the model's search and reading ability and whether the harness makes key tools available by default.
But this is not purely a harness issue. Strong models have a clear fallback pattern here: when the dedicated search path is unavailable, they reframe the task as "use the general tools available to gather evidence." Trace review on Hermes open-environment tasks shows that strong models first recognize the degraded search path, then use terminal + curl to fetch raw HTML, browser console calls to inspect the DOM, and long-page extraction to pull tables and price fields. When pages fail, summaries are too short, or paths return 404, they are more likely to try a second or third route instead of stopping at the first failure.
Weaker models fail more directly. Without stable search, they often repeat browser_navigate on the same URLs or conclude that the task itself cannot be done. In other words, strong models can compensate for part of the harness gap through plan rewriting, tool substitution, and HTML extraction. Smaller models need the harness to make search / fetch available by default and to provide clear failure feedback. The point is not that strong models do not need tools; it is that weaker models need the harness to keep the search path open, while stronger models can route around some of the missing pieces.
4. Co-Design Principles for Models and Harnesses
Putting these slices together, PawBench does not reduce to "which harness is best." It points to a set of co-design principles. Each principle describes a division of labor between model behavior and harness structure.
1. Inform Fully
If the model cannot see something, it effectively does not exist. The harness should explicitly tell it the current working directory, workspace, output directory, whether SKILL.md exists in the workspace, and which resources are available.
This principle addresses weak working-directory awareness and resource discovery. When Hermes does not provide cwd, weaker models are more likely to write files into /home/user/ or /root/. When OpenClaw renders Skill descriptions into the prompt, the model at least knows to read the expert procedure first.
2. Equip on Demand
Tools should be both available and economical. "Available" means key tools should work in the default configuration, such as keyless web search, built-in HTTP fetch, or automatic Skill helper registration. "Economical" means the tool set should match the target model's context and attention budget.
Smaller models are not well served by a giant tool table. Models with brittle long-context behavior also should not receive an oversized system prompt and tool schema all at once. More tools are not always better; too many choices can make execution less stable.
3. Monitor Actively
Don't just listen to what the model says. Check what it actually did. A harness should verify whether required artifacts exist, whether they are non-empty, whether required fields are present, whether tool calls are legal, and whether exit codes are normal.
This principle addresses false completion and weak self-checking. A task is not complete just because the model says "done." It may have written no file, or written the file somewhere the grader cannot see. Artifact-level validation is more reliable than a sentence in the final answer.
4. Recover Gracefully
One exception does not necessarily mean the task is over. When the harness detects an empty response, a plan-only answer, a tool-call error, or a missing artifact, it can give the model a more informative continuation: inject the current state, explain which artifact is missing, keep intermediate results, and set a reasonable retry budget.
This principle addresses early exits, loops, and weak fallback behavior. Models such as qwen3.6-35b-a3b tend to give up after a few tool failures, while models such as kimi-k2.6 can repeat the same action. The harness should explain the state after an exception and push the model toward a new strategy.
Who PawBench Helps
If you are an agent user, PawBench helps you choose a better model–harness pair. Text tasks, multimodal tasks, Skill tasks, and Web Search tasks do not all favor the same pair. Do not look only at the model's total score; also check which harness is stable on the scenarios you care about.
If you build harnesses, PawBench is more than a leaderboard. It gives you a 4,050-cell comparison matrix and slice analysis, which can help with three things:
- Horizontal self-checks: run your harness against the same models and see which task types lag.
- Failure profiling: identify suspicious slices, compare traces, and find concrete harness behavior issues.
- Regression validation: after each fix, re-slice the results and see whether the score change matches the intended repair.
If you build models, PawBench surfaces concrete training targets: working-directory awareness, strategy switching after tool failure, repeated-action detection, stepwise writes in long tasks, fact retention after web search, and safe refusal boundaries. These capabilities may not stand out in chat benchmarks, but they directly decide success in real agent tasks.
This is why the evaluation matters for general-purpose agents. Real users do not stop after one question. They ask agents to operate files, call tools, run scripts, read web pages, and complete multi-step tasks. PawBench breaks those workflows apart so both model capability and harness behavior can be inspected, diagnosed, and improved.
Contributing
PawBench v1.0 is open source. We welcome community contributions:
- Integrate new harnesses, such as CoPaw, Cursor Agent, or other community frameworks.
- Submit new model evaluation results.
- Contribute more tasks and tag them with the five-dimensional taxonomy.
- Use slice analysis on task groups you care about and share diagnostic reports.
PawBench builds on the open agent evaluation community, including Claw-Eval, QwenClawBench, WildClawBench, PinchBench, and skillsbench.